
Bull Series - When Bullish Isn’t Bullish: The Limits of AI Sentiment Analysis in Trading

Recently I’ve been exploring sentiment analysis, one of AI’s most promising and challenging applications, especially in finance. It uses NLP to analyze text into actionable market signals, yet interpreting those signals correctly is far from simple.
Early sentiment analysis tools were fairly basic, using pre-defined keyword dictionaries created manually. For example, if an analyst wanted to detect sentiment around job cuts, they might manually add words like "layoffs," "downsizing," or "reductions." The software would then simply scan documents for these keywords, counting occurrences and assigning an overall sentiment label. While somewhat useful, these methods lacked true “learning” capabilities from embedded data and focused primarily on binary or ternary classification (positive, negative, neutral).
The next step forward for sentiment analysis was the introduction of traditional machine learning models like logistic regression and support vector machines (SVM). These models brought real "learning" into the process, relying on manually engineered numerical features such as word counts or word importance measures like TF-IDF scores to classify sentiment. Although a notable improvement over rule-based methods, these models still had difficulty capturing deeper context and subtle meanings behind financial language.
Today, sentiment analysis tools have significantly advanced, leveraging deep learning through multi-layer neural networks and contextual embeddings. These sophisticated models dynamically learn intricate relationships and context, performing sentence-by-sentence sentiment scoring with detailed probability outputs. Instead of assigning simple binary or ternary labels, modern tools might indicate, for example, a 72% probability of positive sentiment, 20% neutral, and 8% negative sentiment. These detailed probabilities can then be summarized into a scalar sentiment score between -1 to +1 (such as +0.64), providing more nuanced understanding of the text.
Yet, despite these advancements, sentiment analysis still faces challenges when applied practically in financial markets.
Reality Check: Microsoft's Benchmarking Study
A recent study by Microsoft and Santa Clara University compared large language models (LLMs) like Copilot, GPT-4o, and Gemini with traditional NLP tools in financial sentiment analysis. Although some LLMs demonstrated improved accuracy and capabilities over legacy methods on standardized benchmark datasets, they still notably struggled when predicting real market reactions.
In one experiment, researchers segmented Microsoft’s historical earnings call transcripts by business line and used ChatGPT-4o to assess sentiment. They then evaluated whether these signals matched actual stock price movements after the calls. However, they found several instances of sentiment inversion, where a positive tone in certain segments actually correlated with negative stock performance. In these cases, it turned out that optimistic language raised investor skepticism or signaled over-optimism, ultimately leading to sell-offs.
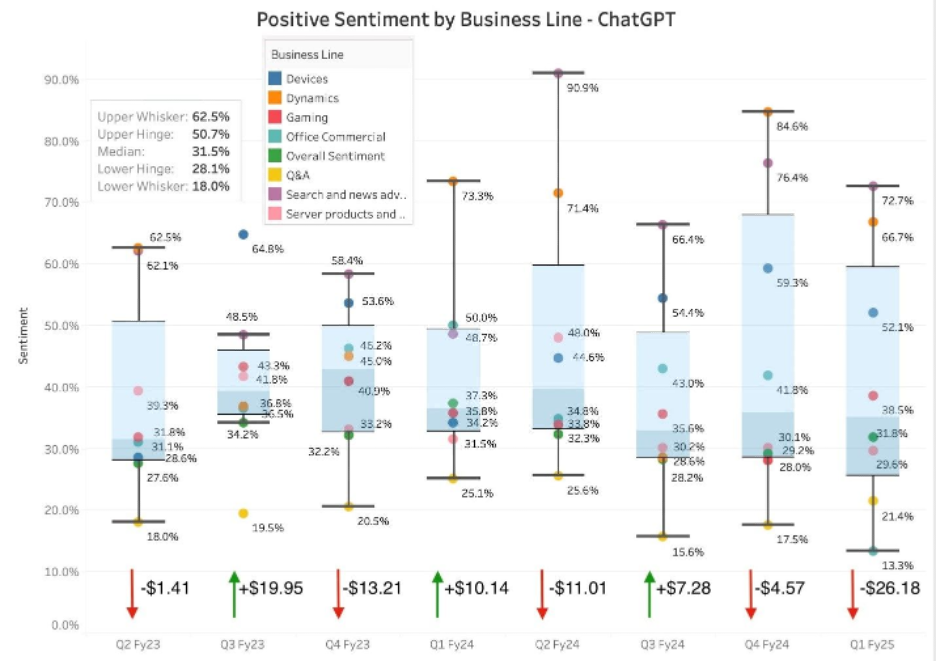
Source: Microsoft 365 Copilot Blog, "LLMs Can Read, but Can They Understand Wall Street? Benchmarking Their Financial IQ," May 2025.
This inverse correlation underscored a key insight and the fundamental challenge in sentiment analysis: not all positive sentiment translates into positive investor sentiment. Tone alone isn’t a reliable predictor of investor behavior - rather, the market responds to expectations, context, and broader narrative shifts taken together.
Tailored Tools for Financial Markets
That said, modern financial sentiment analysis tools represent a notable evolution beyond sentiment systems based on general-purpose LLMs. Sophisticated tools like Alexandria are fine-tuned and context-engineered for financial terminology and scenarios, offering enhanced accuracy and deeper contextual insights. These advanced tools have expanded their training data beyond formal financial texts like earnings calls, press releases, and economic reports - they’re now beginning to cover informal sources like Wall Street Bets forums as well, with models interpreting emojis, slang, and sarcasm.
These tools go beyond surface-level sentiment and prioritize fundamentally driven insights. Rather than assigning positive scores to vague statements like, "We had a fantastic year," advanced models give greater weight to concrete, evidence-based statements such as, "We reduced operating expenses by 15% through improvements in x, y, and z." Similarly, in context-dependent sentences like “Margins expanded due to temporary cost deferrals,” a basic model might flag it as positive based on the margin expansion headline alone, while an advanced tool may recognize that improvements are temporary and potentially unsustainable, and interpret the statement more cautiously.
However, despite these advancements, my conversations with traders and quants reveal that adoption of these tools in live trading workflows remains limited. Although the capabilities have improved, professionals remain hesitant to fully embrace them: some teams feel the cost of using external vendor tools outweighs the potential benefits, while others prefer to develop proprietary sentiment systems in-house. But even then, these internal tools are often used cautiously and as one of many alternative data sources, since making them truly reliable and actionable still requires significant time, resources, and continuous refinement.
The Shortcomings
So where do current financial sentiment tools fall short? While sophistication varies among providers, several overlapping issues persist:
Bias Beneath the Scores
A major limitation lies in biases embedded in the training data and design of these tools, including:
Source bias: sensational headlines or overly optimistic earnings calls that skew sentiment.
Labeling bias: subjective human judgments when tagging text.
Expectation bias: ignoring market reactions relative to expectations (for example, a CEO calls 8% growth “record-breaking,” but the Street expected 10%).
Domain bias: overrepresentation of certain industries or regions.
These biases can lead to misclassifications and misleading signals. Even if models perform well on static benchmarks, in live markets they may fail to capture the true narrative investors care about.
Sentiment is Temporal
While modern tools can track sentiment trends over time and provide historical series, they rarely reinterpret past scores as new market context emerges. For instance, “We’re prioritizing cash preservation this year” might appear negative in a growth-focused bull market but look prudent in hindsight during a downturn that comes soonafter. Even when narratives shift dramatically, tools do not retroactively adjust their original sentiment classifications.
Signal Crowding & Alpha Decay
Another key challenge is signal crowding and alpha decay. As more funds adopt the same third-party sentiment feeds, informational edge quickly erodes. While firms may apply their own proprietary weighting and interpretation to these signals, if the underlying sentiment data is shared, the starting informational advantage is fundamentally diluted.
The Road Ahead
Addressing these shortcomings will be key to transforming sentiment analysis from a “nice-to-have” tool into a core part of trading strategies. Looking ahead, the next generation of AI sentiment tools will need to become more predictive, proprietary, and holistic to truly deliver on their promise.
Deeper Automation & Real-Time Insights
One big step forward will be deeper automation and predictive integration. While sentiment scores today can be automatically generated, interpreting them is still highly manual and strategy-specific. In the future, real-time AI agents built into these tools could deliver instant, contextual signals – for example, an AI agent listening to an earnings call and flagging: “Negative guidance tone detected in XYZ business line. Historically, similar shifts have preceded short-term underperformance in 68% of comparable cases.” Rather than just offering static descriptive scores, these next-gen tools would deliver actionable, historically grounded insights that flow directly into decision-making workflows, bridging the gap between raw data and dynamic strategy.
Signal Differentiation and Proprietary Insights
Beyond automation, protecting alpha will remain a top priority. And the key to doing so will be firm-specific, proprietary sentiment models. Some sophisticated firms are already building hyper-personalized systems, embedding their unique “house view” into AI tools trained on internal notes, trading styles, and research habits. These custom house LLMs wouldn’t just understand broad financial language; they’d also grasp exactly how each team interprets nuanced terms like “margin expansion” or “operational leverage” in their own context. While current third-party solutions offer some configurability, they can’t match this level of deep customization.
Multimodal Analysis
Finally, sentiment systems will keep evolving into true multimodal analyzers, moving beyond just text. Next-gen tools that integrate voice inflection (hesitations, pitch changes) and visual cues (body language, slide design choices) will deliver richer, more human-like interpretations. Imagine a sentiment tool that picks up a CEO’s subtle vocal hesitation during revenue guidance, cross-references it with underwhelming margin slides relative to market expectations, and flags it as a hidden bearish signal – even if the words on paper sound confident.
Taken together, these developments have the potential to elevate sentiment analysis far beyond simple text scoring and turn it into a powerful strategic edge on Wall Street.
What’s your take on AI sentiment tools? Game-changing innovation or just another AI trend? Drop your thoughts below, and let’s keep the conversation going.