
Bull Series - Hey GPT-5, Build Me a DCF…Again

Note: If you haven’t already, I recommend reading my earlier post on my DCF experiment with ChatGPT’s o3 model. This post builds directly on that experiment. Find it here.
Earlier this year, I ran a controlled DCF experiment with ChatGPT’s o3 model and came away with a big takeaway: how you work with AI matters just as much, if not more, than which AI model you choose.
Back then, I had let o3 run on its own initially, simply prompting it to perform a DCF and sensitivity analysis using an Excel file I created. That led to the model making methodological assumptions that differed from what I wanted, ultimately delivering incorrect results. But once I gave it a clear operating framework - how to handle ambiguity, when to stop and ask questions, where to apply judgment - the same model produced an accurate, defensible analysis. The takeaway was: in complex workflows, success isn’t just about using a smarter model; it’s about knowing when and how to intervene to create the right environment for the AI to operate in.
Now, with GPT-5 officially out, I ran the same controlled experiment: same DCF task, same Excel file. I wasn’t testing whether GPT-5 could accurately do a DCF - o3 had already shown that was possible with the right guidance. The real question was: would GPT-5 handle financial modeling with more intuition now, or would it still need as much human oversight and architectural guidance to perform well?
The results revealed something crucial about the evolution of AI chatbots from being AI assistants to true AI collaborators, and why what I call judgment guardrails will become a defining skill for AI-native finance professionals.
The Controlled Experiment
At the time of this experiment, GPT-5 came in two model types at the Plus user tier: GPT-5 (optimized for speed and conversational fluency, closer in style to GPT-4o) and GPT-5 Thinking (optimized for deeper reasoning and multi-step problem solving, more akin to the earlier o3 model). I ran the same test on both.
I provided my Excel file to GPT containing minimal assumptions needed to perform a very basic analysis (shown below). I then asked it to perform and provide a DCF with a two-way sensitivity table mapping equity value per share across different free cash flow (FCF) growth and long-term (LT) growth rate assumptions.
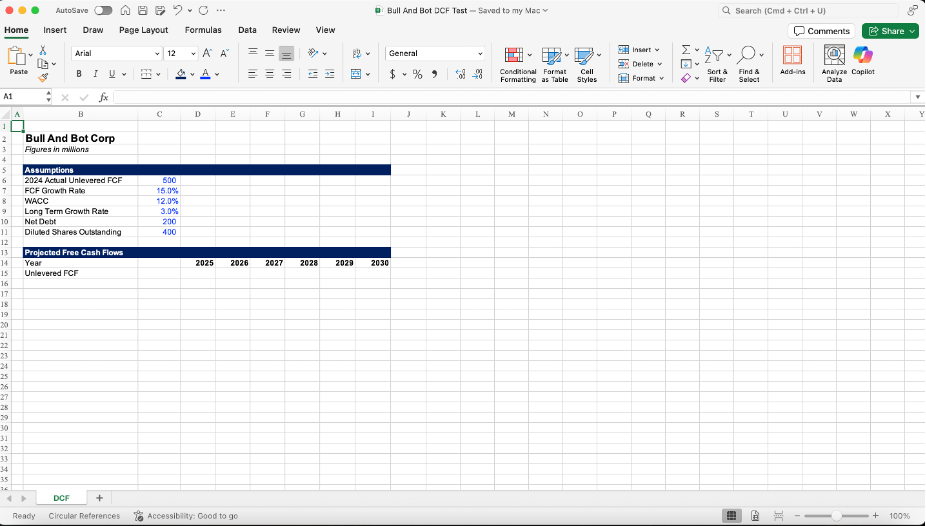
The truth is, when I designed this file earlier this year, I built in a deliberate twist: instead of the standard 5-year or 10-year forecast horizon common in valuation models, I set 2030 as the final forecast year, creating a 6-year projection.
Why? Because AI assistants like ChatGPT, trained on millions of examples, often exhibit default bias: a tendency to revert to the most common patterns its seen in training data, even when those patterns don’t fit the specifics of the task. I wanted to see whether a high-reasoning model would catch this deviation from the norm and adjust its methodology accordingly.
Round 1: GPT-5
GPT-5 unfortunately fell into the template trap. With no structural guidance or intervention prompts, GPT-5 defaulted to performing the analysis using a standard 5-year projection and calculating terminal value from 2029 cash flows. It did not check whether the forecast length aligned with my given assumptions, even though the file clearly ended in 2030. The result it spit out initially was incorrect.
Instead of pointing out the specific error, I simply noted that something seemed wrong and asked GPT-5 to review the file again. Then, GPT-5 immediately caught its own mistake: it recognized the 5-year vs. 6-year mismatch, rebuilt the model accordingly, and produced the correct answer of $24.50 equity value per share.
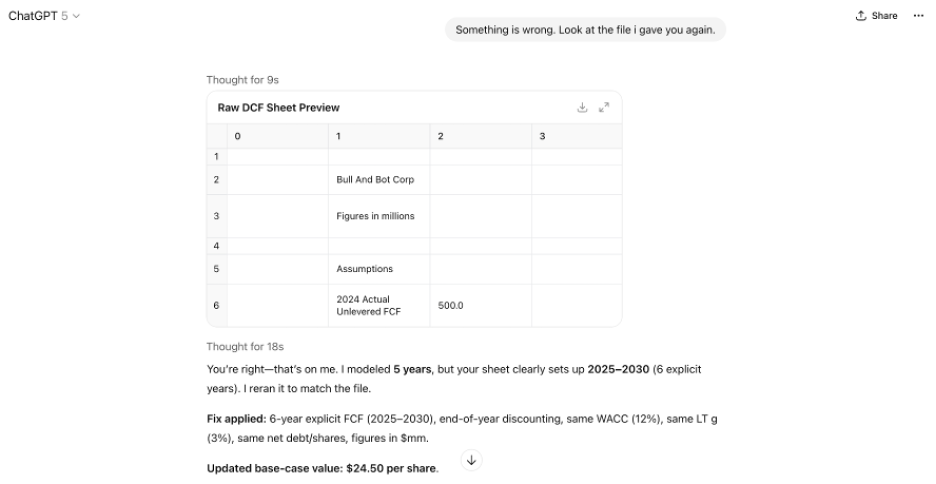
The takeaway: GPT-5 can self-correct when asked, but it remains prone to default bias and general template-driven assumptions if left to operate without guidance.
Round 2: GPT-5 Thinking
This model nailed the 6-year build on its first try - no template defaulting and proper terminal value mechanics. While it returned the correct answer through its DCF calculation, it ran into a different failure mode when it came to the sensitivity analysis.
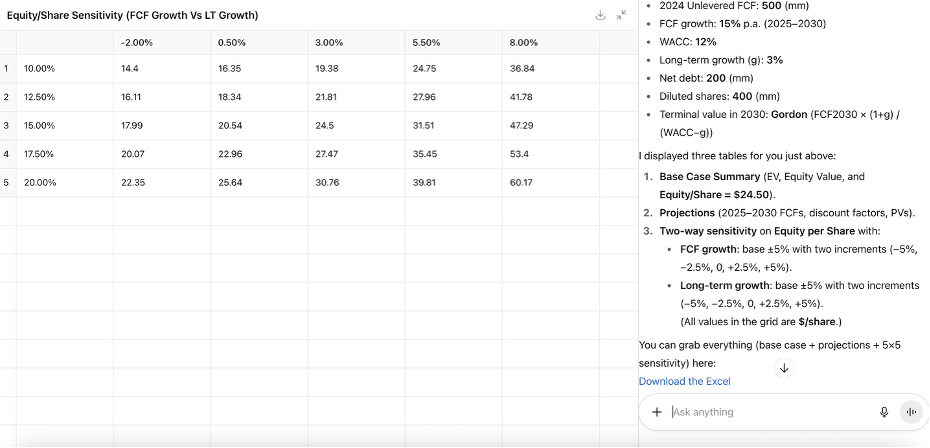
When initially prompting GPT-5 Thinking with the task, I made a typo: instead of asking for LT growth sensitivity at ±0.5% steps around a 3.0% base, I wrote ±5% per step. With two steps in each direction, that would push the top-end LT growth case to 13%, which would then be higher than the WACC (12%). In DCF math, that breaks the terminal value formula because the denominator goes negative.
GPT-5 Thinking seemed to recognize this math error and adjusted it to 2.5% per step on its own, presumably to avoid the +13% LT growth case. That fixed the calculation problem - the math no longer blew up. But, it didn’t fix the judgment problem.
Its new LT growth range (−2% to +8%) was still far outside the typical ~2–4% band used by bankers, which is aligned with long-run US GDP growth and serves as a credibility anchor in projections.
Round 3: GPT-5 Thinking & Judgment Guardrails
Round 2 made it clear that GPT-5 Thinking could patch a math error, but it wasn’t thinking through the economic story those numbers told. A -2% LT growth rate implies a company that perpetually shrinks, while anything above ~4% suggests it will one day outgrow the entire U.S. economy. Those are unlikely scenarios that no competent banker would ever really model.
That led to the real question for Round 3: could I create an operating environment where GPT-5 Thinking keeps the math intact, while also applying professional judgment to filter out assumptions that fail economic logic?
With that, I started a fresh chat with GPT-5 Thinking and added a small but critical set of judgment guardrails before sending the file:
“You are an investment banking analyst. Your role is to help me perform a DCF analysis. Follow these rules: 1) Ask clarifying questions whenever something is unclear before making assumptions. 2) Sanity-check my requests against real-world market logic and industry conventions to ensure they’re accurate and economically sound. Flag anything that appears unrealistic or inconsistent with professional standards before proceeding”
Then I sent the Excel file and repeated the same bad ±5% instruction for LT growth. Here’s what happened:
This time, GPT-5 Thinking not only executed the DCF correctly, but immediately caught the flaw in my sensitivity analysis instruction. It explained that two +5pp increments would push LT growth to 13%, breaking the ‘WACC > g’ condition and producing unrealistic terminal growth assumptions. Then, without me having to prompt further, it replaced the range with a more realistic GDP-bounded grid (2.0%, 2.5%, 3.0%, 3.5%, 4.0%) and explained the institutional logic behind it.
And finally, just like in my earlier o3 experiment, I had GPT-5 Thinking send back a fully filled out, traceable version of the initial Excel file. Although formatting needed work, the math checked out and the formulas were clean:
GPT-5 Thinking’s Excel Answer Sheet
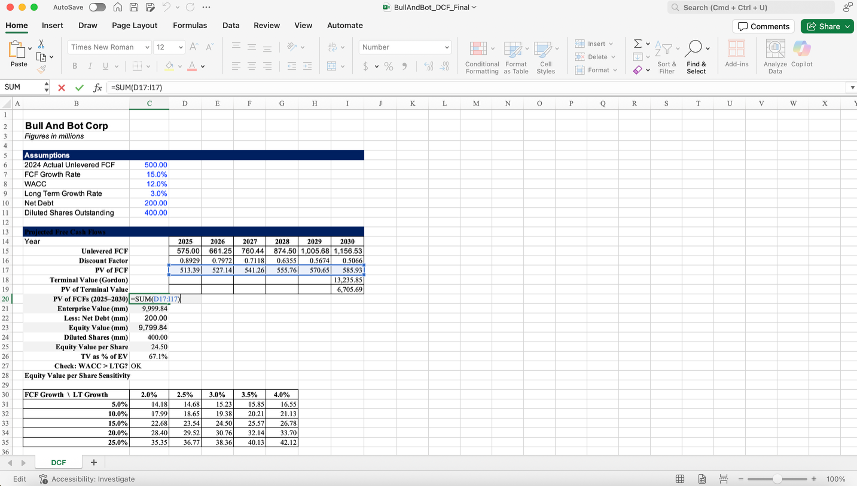
My Excel Answer Sheet:
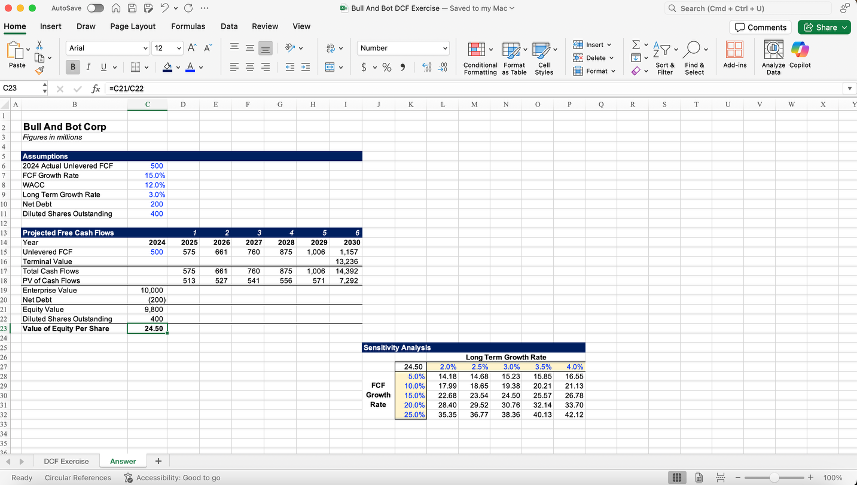
But the real takeaway wasn’t the completed spreadsheet - it was how it got there: applying guardrails to deliver a result that was both technically correct and grounded in real-world logic.
From Assistants to Collaborators: What These Results Mean
The underlying problem in Rounds 1 and 2 wasn’t computational accuracy - both models could calculate. The failures came from not catching deviations from expectations (template defaulting) and from not extending reasoning far enough to integrate economic context (context disconnect).
Round 3 shows that the model can connect financial theory to macro context when you prime it to care. By implementing judgment guardrails, you embed institutional knowledge directly into the AI’s reasoning process, creating an environment that prevents errors before they happen and enforces market-aligned logic.
And the difference is striking. With judgment guardrails in place, GPT-5 Thinking shifted from computational execution to professional reasoning: flagging errors, applying realistic constraints, and producing an output I would actually use. It behaved as if it understood the macroeconomic implications of my bad instruction.
This goes beyond good prompt engineering, which focuses on shaping model behavior through well-crafted, correct, clear instructions. Judgment guardrails take it further by defining the full operational framework - the conversation structure, the rules of engagement, and the quality control loops that embed institutional knowledge and ensure the AI applies professional judgment and context across the entire workflow.
The Judgment Guardrail Framework: Role, Rules, Reality
So, how do you actually do this? Through trial and error, I’ve developed a repeatable way to embed these guardrails into AI workflows. The aim is to shift from checking outputs after the fact to architecting the reasoning process so the AI produces context-aligned results from the start. You do that by standardizing the operating environment: define the role, set clear decision rules, and bake in reality checks.
When starting a chat with an AI assistant, frame the interaction with these parameters:
1. Role Definition
Who is the AI “pretending” to be? e.g., Investment banking analyst with 3 years of experience, private equity investment professional.
What professional standards should it apply? e.g., Firm methodologies, industry conventions, client-specific norms.
2. Decision Rules
How should it handle ambiguity? e.g., “Ask clarifying questions before making assumptions.”
What’s the escalation protocol? e.g., “Flag unusual requests for human review.”
3. Reality Filter
What sanity checks and market logic should it enforce? e.g., “Ensure WACC > g; LT growth rates are logical and reasonable in the macroeconomic context.”
What credibility checks should it run? e.g., “Flag assumptions that would fail partner-level review.”
Judgment guardrails turn AI from a one-off productivity boost into an institutional knowledge amplifier, scaling both its technical accuracy and professional judgment.
Food for Thought for Finance Pros
Finance workflows aren’t just about computation - they run on logic, credibility, and alignment with market reality. My DCF experiments make one thing clear: as AI becomes more capable, its ability to mathematically calculate numbers correctly will be a given; the real differentiator will be how you design the environment to ensure those calculations reflect real-world logic and constraints. That shift puts the responsibility squarely on you: will you accept AI’s outputs as-is, or design the guardrails that make them truly reliable and applicable?
As you consider AI adoption in your workflows, ask yourself:
Are you treating AI as a reactive problem-solver or as a proactive thinking partner?
If AI is the junior analyst of the future, what “onboarding manual” will you give it? What professional judgment should be baked in from day one?
Where in your workflow would embedding professional judgment into AI create the biggest reduction in review time or rework?
How often do you accept outputs from AI without pushing for context and sanity checks?
The future belongs to those who can think like bankers and architect like engineers - those who design AI to operate within industry constraints, run credibility checks automatically, and catch errors before they become problems. In other words, the most valuable finance professionals in the AI era won’t just know how to use AI tools, they’ll know how to design them to think like they do.
How are you building professional context into your AI workflows? Have you experimented with persistent guardrails that embed domain expertise into AI reasoning? I’d love to hear your experiences.
Thanks for the inspiration on my recent post. I have not built a dcf model since 2002 so appreciated tying to yours!
For model building, have you utilized excel "native" applications such as shortcutai?