
Bot Series - I Tried Breaking ChatGPT’s 'New' Image Generator: Here’s What I Learned (Part 1)

Ever since ChatGPT rolled out its upgraded image generation model two weeks ago, the internet’s been buzzing. While much of the discourse has focused on GPT’s uncanny ability to mimic the styles of studios like Ghibli or Disney, one thing is undeniable: this update marks a major milestone in the evolution of multimodal AI.
Prior to the upgrade, ChatGPT didn’t generate images itself. When a user requested an image, ChatGPT crafted a text prompt and sent it through an internal API-style like call to Open AI’s image generation model, DALL-E, which was hosted on a separate system. GPT then returned to the user with an image generated by that model.
Said more simply, it’s like ordering food from a restaurant: your server (ChatGPT) took your order from the dining room and then disappeared into the back kitchen to tell the chef (DALL-E), who did the actual cooking. Same restaurant, different jobs, different setups.
Now, with OpenAI’s recent upgrade, ChatGPT can natively generate and edit images. Image generation is no longer handled by sending prompts to DALL-E or any external model. Instead, both text and image generation are unified within a single, multimodal architecture which handles these tasks natively, without relying on separate systems.
So now, its like you’re sitting at the chef’s counter in an open kitchen restaurant: you still speak to the server who understands your taste. But instead of running off to a different room, the server just leans over and says, “Hey Chef, give us a double cheeseburger with extra jalapenos.” Then right in front of you, the chef gets to work. Same restaurant, different jobs, same setup.
Alongside this architectural shift, image generation itself also got noticeably better. It became sharper at interpreting prompts, composing coherent scenes, and responding to nuanced or stylistic requests. Although native inpainting (advanced photoshop-level editing capabilities) continues to remain available to Plus-users, the image generation upgrades, which are now accessible to users across all tiers, have been fun to play around with.
Since the upgrade, I’ve been exploring and testing the limits of ChatGPT’s new image generation and editing capabilities as a Plus user. I ran a series of experiments to understand the strengths and limitations available at this tier. Given the depth of insights from these experiments, I've split the debrief into two parts. In Part 1 (this post), I'll cover GPT’s ability to handle procedural visuals: i.e. how well it performs in generating step-by-step instructional images that demand visual logic and precision. In Part 2 (next post), I’ll dive into GPT’s strengths in narrative creativity and examine key limitations in its visual memory.
1. Procedural Visualization – GPT’s Strengths and Weaknesses
First, I wanted to see GPT’s ability to generate clean, step-by-step visuals for real-world processes. In other words, I was testing its ability in procedural visualization: turning a simple prompt into a clear, Pinterest-style how-to board, showcasing not just a single image, but a visual sequence broken down step-by-step. For this experiment, I ran three different scenarios with GPT: preparing overnight oats, making pour-over coffee, and illustrating how to use a roman chair back extender.
Overnight Oats (Success)
Creating a visual guide for overnight oats was smoother than I'd expected. I asked GPT for a blueberry overnight oats recipe, prompting it first to share the steps and then turn them into a four-panel visual guide. Impressively, GPT quickly generated a photographic-style sequence: oats, milk, chia seeds, and blueberries, stacked neatly in clear, logical steps. There were a few minor issues, like the text beneath each panel being partially cut off or chia seeds appearing prematurely, but after a handful of iterations, GPT produced a polished visual guide.

Why did GPT handle this task so effectively? Because it excels at photographic sequencing, which involves replicating predictable real-world visuals its seen countless times in its training data. GPT is great at generating ‘accurate’ images when it recognizes familiar patterns, by leveraging the vast database of recipe blogs, Instagram posts, Pinterest images, etc that its been trained on. However, its lack of deep understanding, such as cause-and-effect relationships, spatial logic, or physics, became more and more apparent in subsequent experiments.
Coffee-Making (Somewhat Success)
Next, I tried a 2D infographic-style visual guide for making pour-over coffee. This one, however, proved trickier. Though GPT was still great at summarizing the overall step-by-step process, it struggled much more with illustrations for each step. Here’s what it came up with at first:

Right – not quite what I was looking for, although Steps 1 and 4 were actually pretty good. From there on out, this image required a lot more input and specific instructions to get Steps 2 and 3 right. It especially had a hard time getting Step 2 right as it repeatedly showed coffee already in the beaker before pouring water:
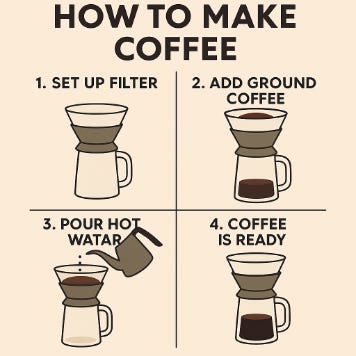
The difficulty that GPT was having illustrates its "default bias": the invisible assumption it forms from repeatedly seeing specific outcomes during training, causing it to default to those common visuals. If you do a quick google search for "pour-over coffee," you’ll see that most, if not all, images show ground coffee in the filter and brewed coffee already in the glass beaker. Presumably, GPT was trained with these images and many more like it, reinforcing this bias. And since GPT doesn’t truly understand the logic of physical processes, spatial relations, or step-by-step constraints, instead of thinking “the beaker must be empty because we haven’t added water yet,” it just tries to match common visual patterns of “coffee setup.” And turns out most often, that picture usually includes coffee already visible in the beaker.
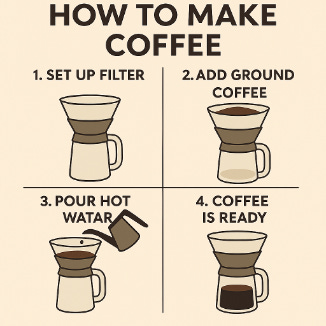
Overcoming this default bias required active negation and precise context control. It took multiple explicit corrections (and me shouting at GPT) before finally getting the sequence right (though you’ll also notice that it struggled to get the word ‘water’ right after a series of iterations):
Back Extension Exercise (Fail)
The most challenging procedural visualization task I asked GPT to do was to demonstrate how to use a roman chair back extender.
GPT repeatedly failed, struggling severely with capturing correct anatomical positioning and motion phases in every step. Unlike overnight oats or coffee-making, this task demanded nuanced visual logic and anatomical accuracy, clearly exposing GPT’s significant limitations in generating precise physical instructions.

As you can see, there’s just… too many wrong things here. Not only did GPT struggle with fitting all four panels within the image frame, but despite my best attempts to provide detailed, panel-by-panel instructions, GPT consistently failed to illustrate subtle movement changes between steps, like noting the difference between “mid-rep” or “peak contraction.” Capturing precise body movements, especially those requiring anatomical accuracy like torso alignment or proper hinge mechanics, is difficult for GPT.
Additionally, it had trouble maintaining consistent visual identity across panels: on close inspection, you can see that the man’s face slightly changed in each step. Realizing this, I considered whether explicitly generating and "anchoring" an image of a figure first might help maintain more visual consistency. And so that’s exactly what I decided to do in the next experiment.
Amazing information, I followed !